Scraping¶
hircine comes with a generic scraper interface that allows scraping comic metadata from virtually any source. Refer to Plugins if you want to write your own.
Scraper sources¶
Usually, a scraper will access a location on the web or a local file on your
disk. The former may be an online API, whilst the latter may be a JSON file like gallery-dl’s info.json.
For local files, two locations are considered. The comic’s archive may contain
this file, or it may be stored as sidecar file alongside the archive in the
content/ directory.
Archive & sidecar files¶
Sidecar files need to be prefixed with the full name of the archive. For
example, if a scraper accesses a file named info.json for an archive
Hoshiiro GirlDrop Comic Anthology.zip, the following locations will be
considered:
Location |
Name |
|---|---|
Archive |
|
Sidecar |
|
Note
If a file exists in both locations, the sidecar file is preferred.
Scraper interface¶
If a comic has scrapers available, they will be shown in the Scrape tab. Selecting the desired scraper and clicking on the Scrape button will start the scraping process.
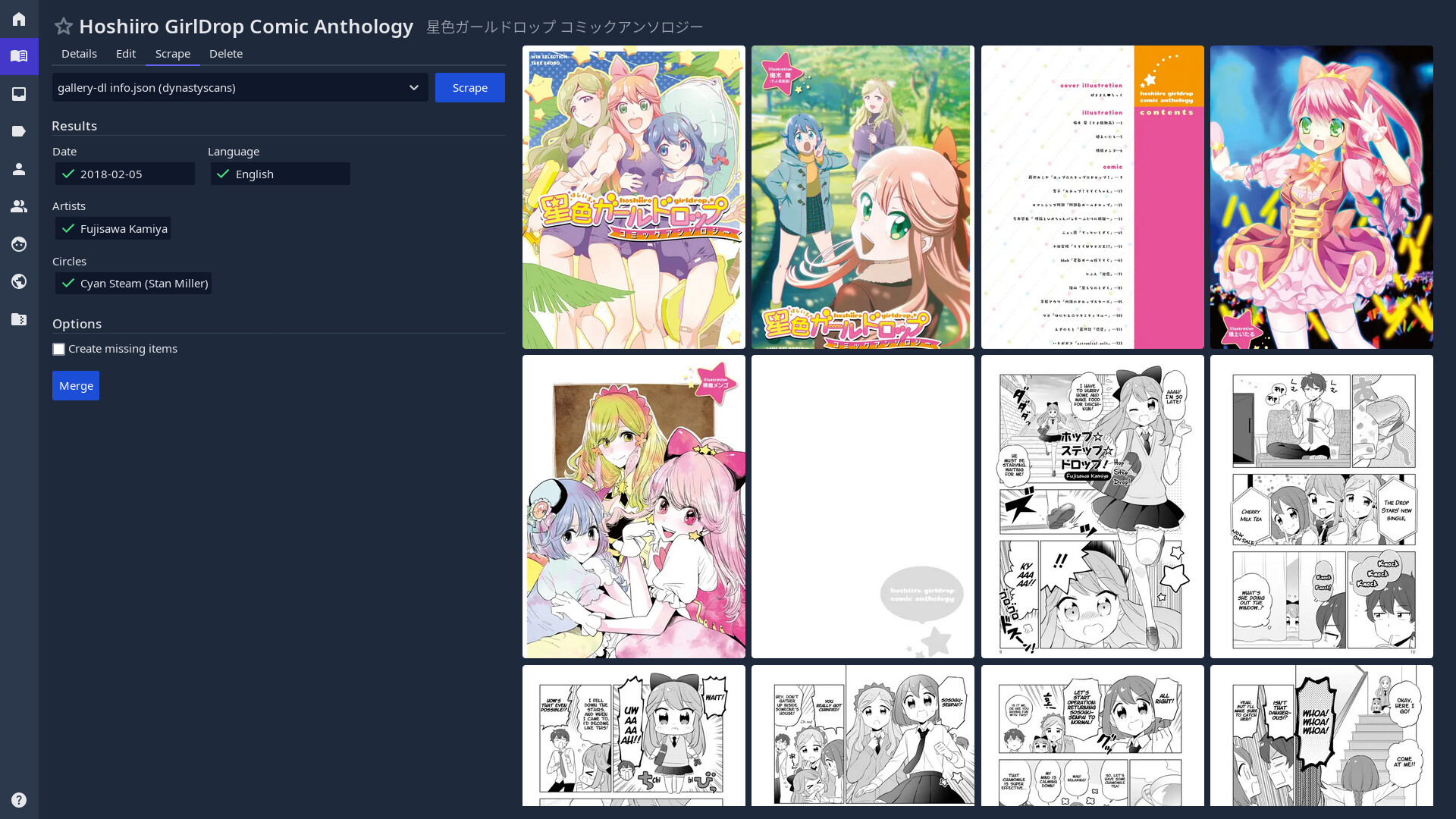
Once the scraper has returned results, they are shown in the pane below. Only results that differ from existing comic metadata will be displayed.
Metadata that should not be kept may be deselected. For groups with a larger set of entries, the selection may be inverted to quickly deselect the whole group, or to only select a few entries. Pressing the Merge button will update the comic with the selected metadata.
Options¶
By default, hircine does not automatically create missing metadata entries. This can be controlled using the Create missing items option.
Note
Scrapers always return qualified tags (the namespace
is set to none if it could not be determined). When requested to create
a missing qualified tag, the namespace and tag will be created (if needed),
and the tag will be marked as applicable to the namespace.
A qualified tag is considered to be missing if any of the following apply:
The namespace does not exist.
The tag does not exist.
The tag is not applicable to the namespace.
Modifying scraper results¶
hircine allows modifying results that are returned by a scraper without having to change the scraper logic. Refer to the documentation on Plugins for more.